The Intern👋
Hi! I'm Shao En. I am an AI Engineer intern at Bifrost. I'm incredibly grateful to have this opportunity to work in the exciting field of synthetic data, alongside an incredibly talented team of engineers and scientists. I’m on the Applied AI team where we battle test and refine our synthetic data to build high performance and robust AI systems.
TL;DR: We managed to beat the state of the art in synthetic-trained aircraft detection within a week using Bifrost synthetic data. Take a look!
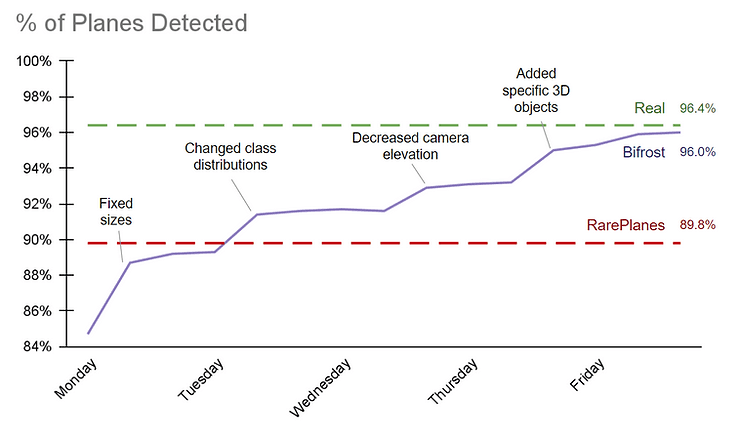
Evolution of performance on real satellite imagery over many synthetic dataset iterations
The Current State 📕
There are other teams out there doing great work with similar approaches, but the best publicly-available synthetic dataset for aircraft detection at the moment is the RarePlanes dataset from AI Reverie.

The RarePlanes synthetic dataset
We trained a Faster-RCNN model purely on the RarePlanes synthetic dataset. Impressively, it managed to detect 90% of all the planes in the RarePlanes real test set. However, I noticed that it failed to generalize for military aircraft and some of the rarer civilian aircraft.

Real planes detected and missed by a model trained on the RarePlanes synthetic dataset
One of the main benefits of using synthetic data is that it allows us to capture rare instances. As such, even though we were able to detect 90% of the planes, I was sure we could do better for the rarer 10%.
The Tooling 🔧
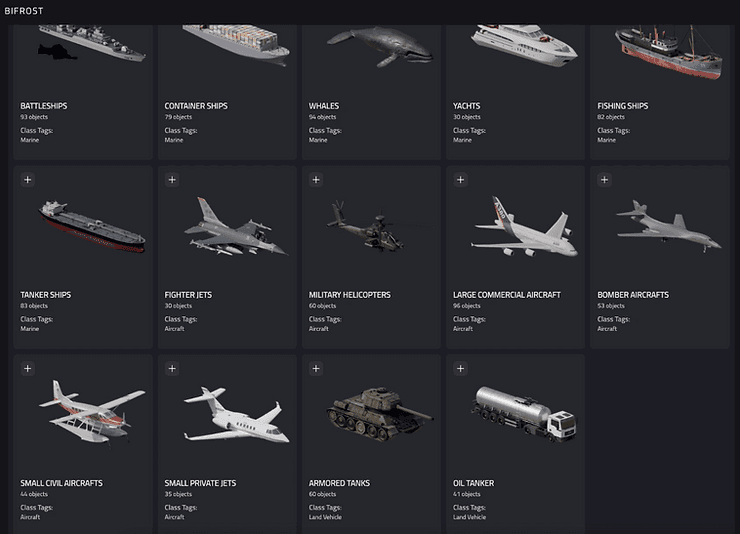
The object configuration and asset store panel where we can view the simulation ready 3D assets
Initially, I was surprised by the array of options available in Bifrost, Bifrost’s synthetic generation platform. Every parameter was under my control: which 3D assets to use, what kind of weather I wanted, and even the sun's location.

A closer look at the physically accurate 3D assets from the Bifrost library
But after getting familiar with it, it was as simple as pressing play. Right there and then, a dataset was generated before my eyes - ten thousand images in half an hour.
The Process 🔃
For my first synthetic dataset, the sizes of the planes were off. The planes were way smaller than they needed to be. This resulted in a model that didn't perform too well on the real validation set that we split from the real training set.
Fixing that was pretty simple. All I had to do was calibrate the scaling ratios to match the synthetic sizes to the real-world ones.
After 30 minutes of generating another dataset and a few hours of training the model, we hit a comparable result to RarePlanes’. I noticed that most of the missed planes were captured at an abnormally low satellite capture angle, resulting in severe warping of the plane from the camera's perspective.

Examples of varied capture angles in the real validation set
With synthetic data, it was simple to tackle this bug. By adjusting the camera angle ranges in the synthetic generation platform, I simulated the warping effect. Afterwards, we could patch the original dataset with a smaller additional dataset which included the more extreme angles.

An example of how different parameters for the camera elevation can change the appearance of the object. The left image features a small elevation angle while the right image features a larger elevation angle
After running the experiments again, we observed another boost in detection rate, surpassing RarePlanes results by a considerable margin! Even though the results were good, we still missed some of the more obscure planes. We needed to include a more diverse range of assets in the dataset to combat this.

Examples of civil and military aircraft of all sizes from the real validation set

Physically accurate procedurally generated 3D planes
While hand-crafting 3D assets to include weird planes is a viable option, it isn't as scalable when we need to generate 20 different variations of a plane class. Fortunately the Bifrost asset library contains procedurally generated planes , physically accurate 3D models defined by rules and parameters. This allows us to produce thousands of models in order to tackle the diversity problem.
The Results 📈
After adding the newly generated procedural planes and combining the insights from the past experiments, I ran the model against the real test set. It was able to detect 96% of all the planes (including the rare military aircraft). To put this metric in perspective, the model trained on the RarePlanes dataset detected 90% of the aircraft.
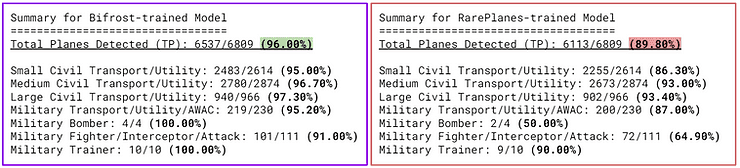
Bifrost synthetic training data helps models learn to detect real planes with a higher recall, compared to RarePlanes synthetic training data.
After a week of experiments and dataset iterations, we'd beaten the current state-of-the-art!
For context, I also trained a model on real data, and it was able to detect 0.4% more planes in the real test set. This was indeed slightly higher than our synthetic dataset. Interestingly, our synthetic dataset performed better than the real dataset for some of the classes (including military fighter aircraft!). Here’s the summary for that:
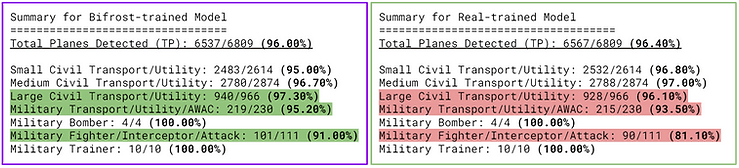
Bifrost synthetic training data helps models learn to detect some real planes better than real training data, especially large civil aircraft and military aircraft.

Visual comparison of model detections on rare aircraft in the real test set. Models are trained on RarePlanes synthetic data, Bifrost synthetic data, and real data.
Before I joined Bifrost, I saw synthetic data as a supplement to real data, not a replacement. I assumed that there was an implicit tradeoff between convenience and performance. But the fact that we're less than 1% away after a week of experimentation proves that synthetic data can outperform real data!
The Next Steps 💡
Looking at this initial synthetic dataset, there is still much room for improvement - patching the dataset with more assets, applying domain adaptation to bridge the visual gap between synthetic and real data, performing smarter placements of assets (rather than spread randomly). We’ve only just begun to scratch the tip of the iceberg.
Reflecting upon the week, I was so caught up in generating datasets and running experiments that I failed to stop and appreciate how amazing this systematic workflow was. In my previous job, I dreaded data collection and data engineering since it bottlenecked the research and iteration process by a considerable amount, preventing me from focusing on the fun stuff.
But now, the process has been cut down from weeks to minutes. As an AI engineer, synthetic data has been incredibly empowering as it allowed me to have complete control over my data and allowed me to iterate over new datasets with lighting-fast speeds. Stay tuned for a more in-depth technical breakdown and to see what benchmark we tackle next!

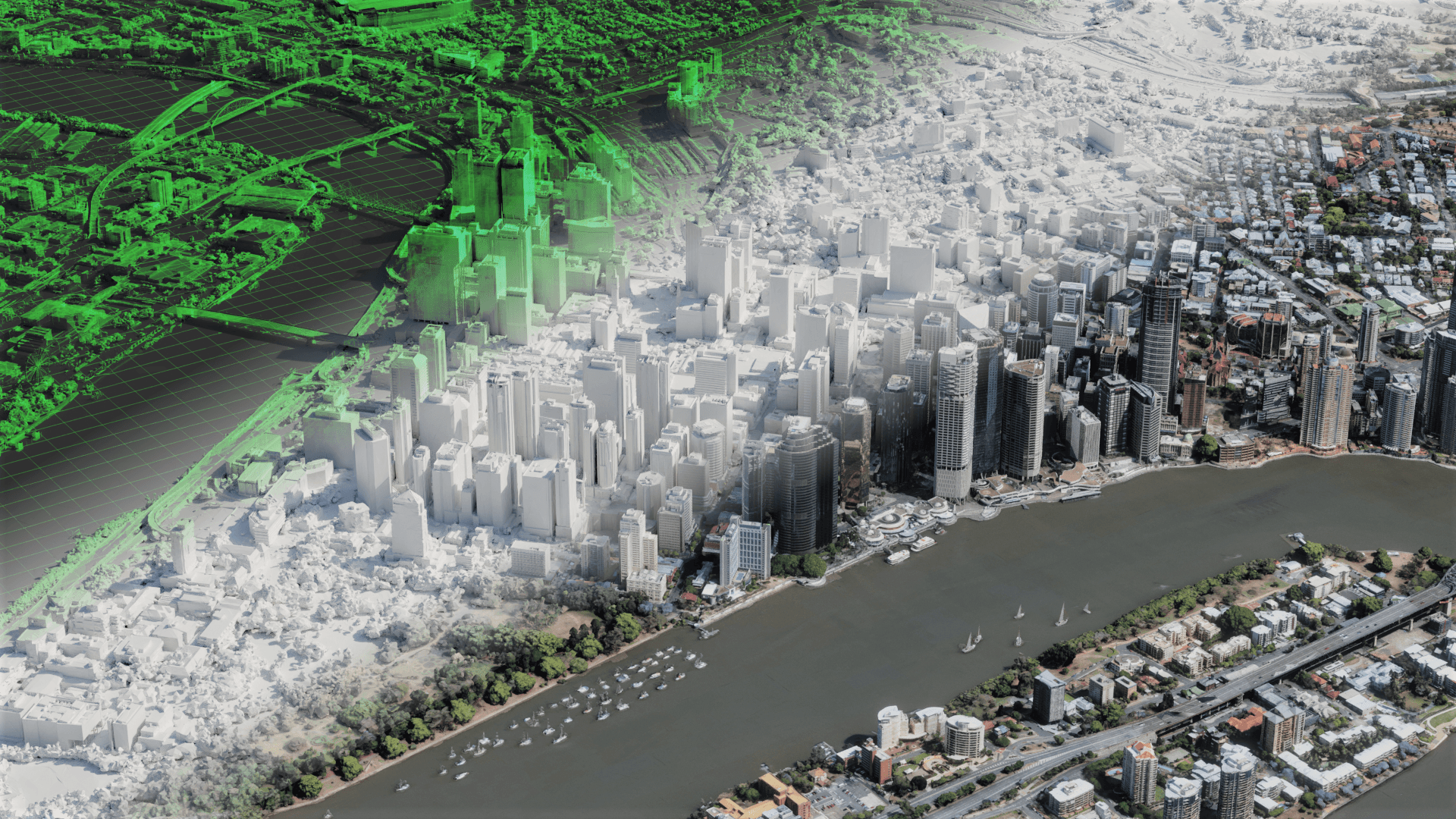
Examples of Bifrost synthetic imagery in their various applications